
Earlier this year when I was in Austin, my friend Andy Sernovitz introduced me to a new startup called data.world.
What caught my interest is that they are building a platform to make data science and discovery easier, more accessible, and more collaborative. I love these kinds of big juicy challenges!
Recently I signed them up as a client to help them build their community, and I want to share a few words about why I think they are important, not just for data science fans, but from a wider scientific discovery perspective.
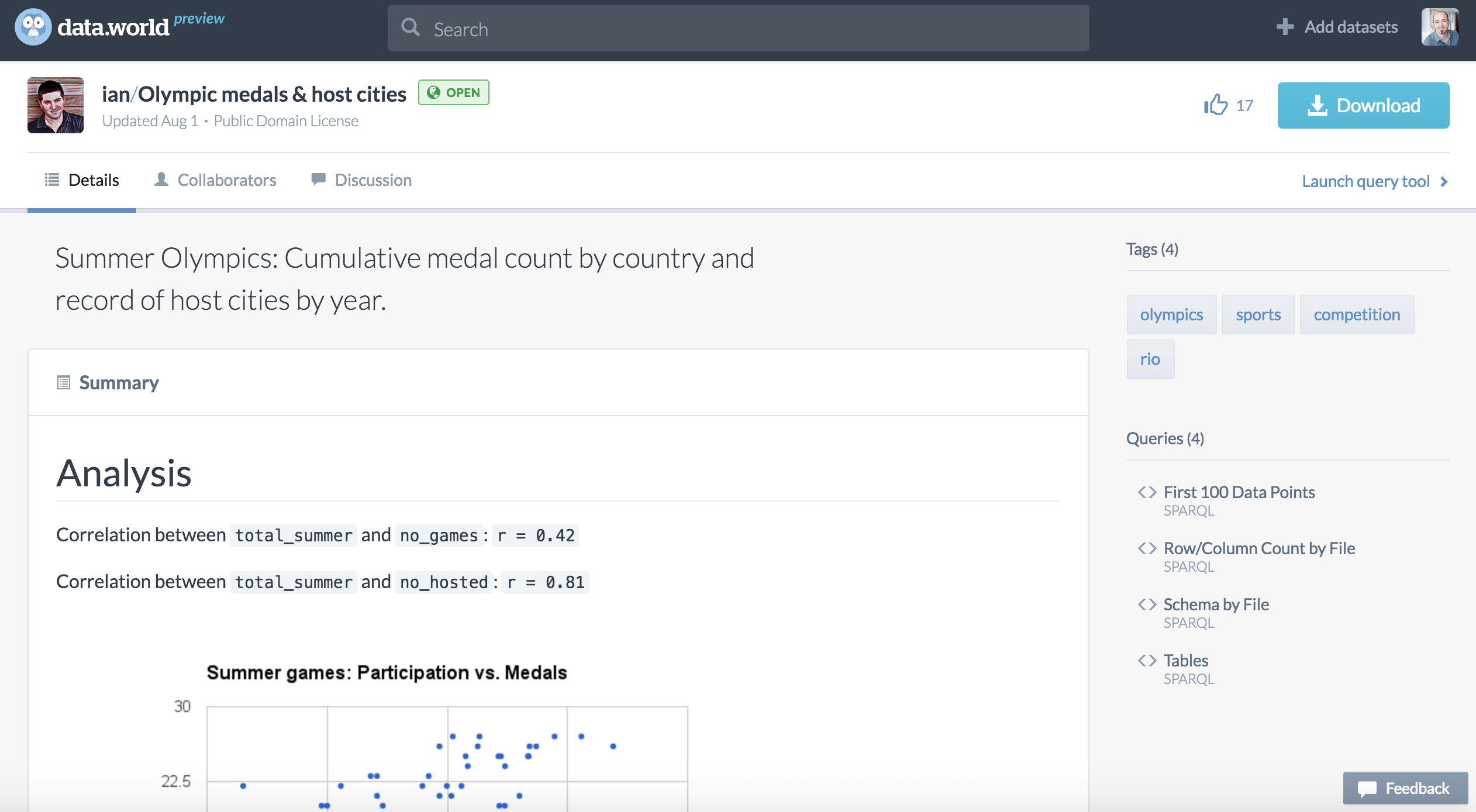
Armchair Discovery
Data plays a critical role in the world. Buried in rows and rows of seemingly flat content are patterns, trends, and discoveries that can help us to learn, explore new ideas, and work more effectively.
The work that leads to these discoveries is often bringing together different data sets to explore and reach new conclusions. As an example, traffic accident data for a single town is interesting, but when we combine it with data sets for national/international traffic accidents, insurance claims, drink driving, and more, we can often find patterns that can help us to influence and encourage new behavior and technology.
Many of these discoveries are hiding in plain sight. Sadly, while talented data scientists are able to pull together these different data sets, it is often hard and laborious work. Surely if we make this work easier, more accessible, consistent, and available to all we can speed up innovation and discovery?
Exactly.
As history has taught us, the right mixture of access, tooling, and community can have a tremendous impact. We have seen examples of this in open source (e.g. GitLab / GitHub), funding (e.g. Kickstarter / Indiegogo), and security (e.g. HackerOne).
data.world are doing this for data.
Data Science is Tough
There are four key areas where I think data.world can make a potent impact:
- Access – while there is lots of data in the world, access is inconsistent. Data is often spread across different sites, formats, and accessible to different people. We can bring this data together into a consistent platform, available to everyone.
- Preparation – much of the work data scientists perform is learning and prepping datasets for use. This work should be simplified, done once, and then shared with everyone, as opposed to being performed by each person who consumes the data.
- Collaboration – a lot of data science is fairly ad-hoc in how people work together. In much the same way open source has helped create common approaches for code, there is potential to do the same with data.
- Community – there is a great opportunity to build a diverse global community, not just of data scientists, but also organizations, charities, activists, and armchair sleuths who, armed with the right tools and expertise, could make many meaningful discoveries.
This is what data.world is building and I find the combination of access, platform, and network effects of data and community particularly exciting.
Unlocking Curiosity
If we look at the most profound impacts technology has had in recent years it is in bubbling people’s curiosity and creativity to the surface.
When we build community-based platforms that tap into this curiosity and creativity, we generate new ideas and approaches. New ideas and approaches then become the foundation for changing how the world thinks and operates.
As one such example, open source tapped the curiosity and creativity of developers to produce a rich patchwork of software and tooling, but more importantly, a culture of openness and collaboration. While it is easy to see the software as the primary outcome, the impact of open source has been much deeper and impacted skills, education, career opportunities, business, collaboration, and more.
Enabling the same curiosity and creativity with the wealth of data we have in the world is going to be an exciting journey. Stay tuned.





